
There are tools that appeared before the invention of the internet, before Linux, before Python, and they still work on every server you log into. grep, sed, and awk are three programs from the 1970s, born in the legendary Bell Labs, that have been the foundation of Unix text processing for over half a century.
grep, sed, and awk have survived every revolution: the PC, the web, the cloud, containerization, and now the era of generative AI. They come preinstalled on every Linux, every macOS, every BSD, every production server. Even on minimal Alpine images that weigh 5 MB. No dependencies. No interpreter required. They’re just there.
grep-sed-awk.com
I’m a huge fan of Unix and its history. I work with text and data processing professionally, so grep, sed, and awk are everyday tools for me. I wrote grep-sed-awk.com because I wanted a place like this for myself – with a handy cheat sheet and practical examples. I believe the tools and the people who created them: Thompson, McMahon, Aho, Weinberger, Kernighan – deserve yet another proper place on the web 😉
grep-sed-awk-com.com
grep, awk, and sed in the age of AI
In 2026 you can ask AI to write a script, analyze logs, or generate a report from data – in a single natural language sentence. So why bother with three programs written in the 1970s?
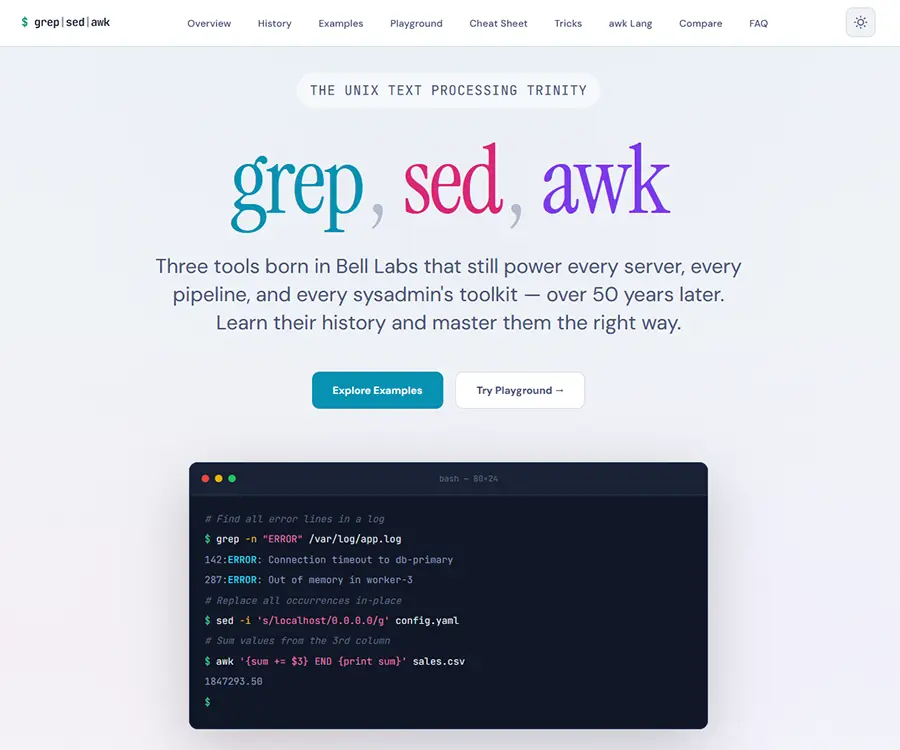
Because grep, sed, and awk do something no language model can: they work locally, deterministically, and instantly. grep "OOM" /var/log/syslog | awk '{print $1, $2, $3}' gives exactly the same result every time, in milliseconds, with no internet connection, no API token, no hallucinations. AI is probabilistic — these tools are precise. And that’s exactly why I created grep-sed-awk.com — a complete guide to these three tools that brings together their history, practical use cases, and an interactive playground in one place.
What you’ll find on grep-sed-awk.com
- History from Bell Labs – a timeline that starts with Ken Thompson writing grep in a single night in 1973, through the creation of sed (Lee McMahon, 1974) and awk (Aho, Weinberger, Kernighan, 1977), all the way to the latest gawk 5.4 release in 2026 with its new MinRX regex engine. The historical context helps you understand why these tools look the way they do – and why they’ve survived decades of technological change.
- Examples from basic to battle-tested – each tool has its own learning path.
grepstarts with recursive search and regex pattern matching, then moves to context filtering and multi-pattern workflows.sedcovers find and replace — both single occurrences and in-place edits across thousands of files — as well as line deletions and capture group substitutions.awkgoes from printing a single column with a custom field separator to full aggregation, statistics, and report generation. The examples come from real work — log analysis, bulk configuration changes, data extraction from CSV files. - Interactive playground – type a command, provide input, and see the result right in your browser, without launching a terminal. Perfect for learning and for quickly testing ideas.
- Cheat sheet and tricks – a condensed table of the most useful flags and commands to keep at hand, plus a section with advanced tricks: hold space in sed, getline in awk, color highlighting in grep pipelines.
- Tool comparison – a side-by-side table that helps you pick the right tool for the job. In short: grep finds, sed changes, awk computes.

Ken Thompson (seated) and Dennis Ritchie at Bell Labs, circa 1970, in front of a PDP-11 – the machine where Unix, and with it grep, sed, and awk, came to life (Photo courtesy of the Computer History Museum)
Regardless of your level – if you work with text in a terminal or process data, reports, or logs, these three tools: grep, sed, and awk are still the shortest path from problem to solution. And grep-sed-awk.com is my attempt to gather that knowledge in one accessible place — so it’s easy to reach for before you even get a chance to open a chat with AI.





